
In this post, I want to share with you the results of a program involving natural language processing and machine learning tools. The aim of the program is to provide insights into Dutch case law developments on a weekly basis, using case law published on www.rechtspraak.nl. As the program is still in beta, feel free to comment or make suggestions. I use Python as a main language and use several different packages for data analysis and visualization.
1. Number of cases by institution and area of law
I collected the ECLI numbers of all cases published between October 12-18 via site’s API (more info) and downloaded the contents of the cases on a local hard drive. In total, 301 cases were published (list).
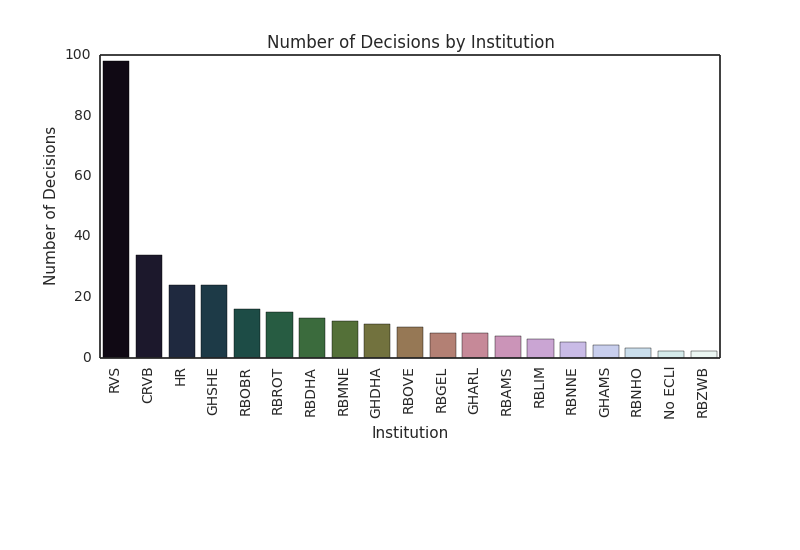
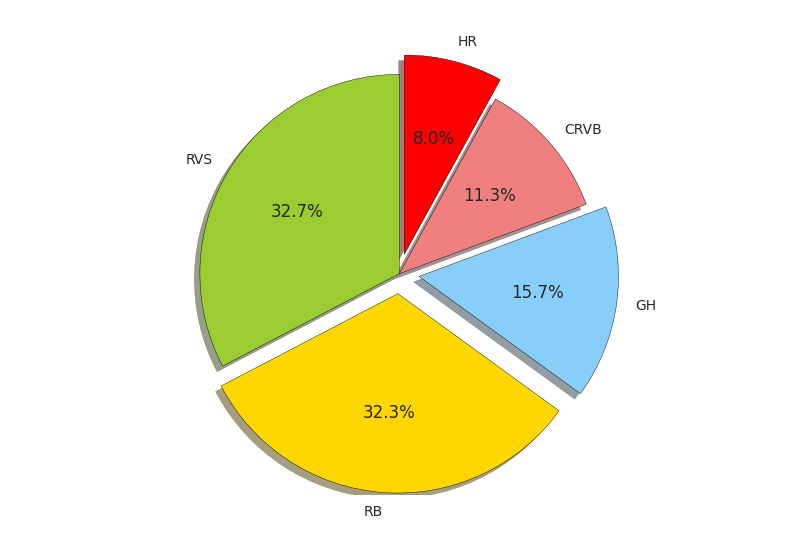
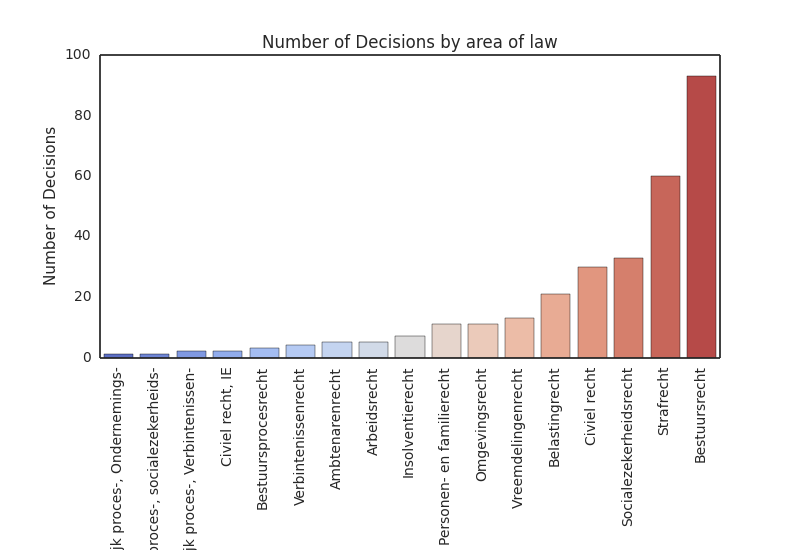
2. Court-specific metrics: output and throughput
While it would be interesting to analyze the workload of individual courts, rechtspraak.nl does not publish the number of filings at each court. As the United States Courts website illustrates, providing those numbers is feasible. Without filing info, analyzing workload is impossible. Instead, I look at the throughput time: the time it takes the court to publish the decision after issuing the verdict. An interesting question, to consider in the future, is its relation to decision length and case complexity.
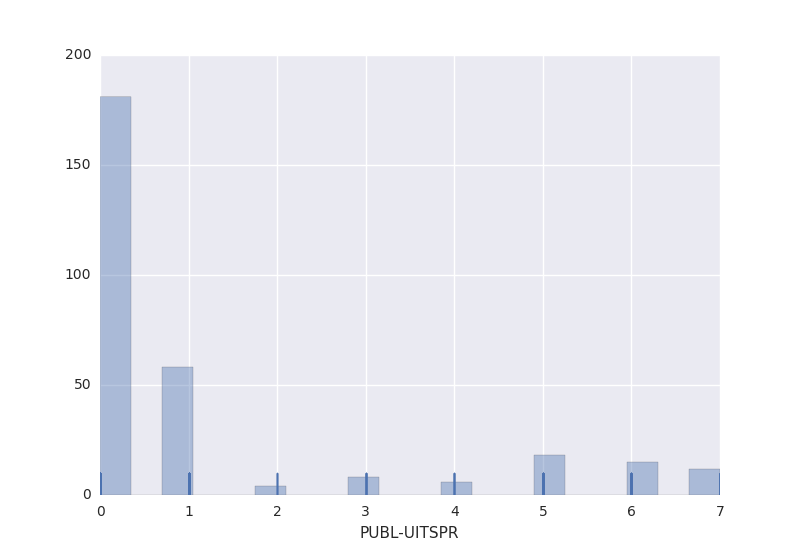
In most cases, the decision is published on the same day. There does not seem to be a general relation between the throughput time and area of law (PUB_area) or court (PUB_instantie). More data is needed to unearth the explanation for this distribution.
3. Text features: basic unigram classification
In terms of structure, court decisions are simply long and unstructured text strings. There are numerous natural language processing techniques which facilitate statistical analysis of these text strings by extracting features, some of which I will use in the future (e.g. POS Tag sequences, Hidden Markov Models, Deep Learning, ontologies). In this QNL, I restrict the analysis to “unigrams” or individual words. This bag-of-words approach is simplistic, but suffices for exploratory purposes. After preprocessing (Feldman & Sanger 2007), I count the word frequency for ECLI:NL:HR:2015:3091, a decision issued by the Supreme Court, and posted the result in a word cloud:

The main drawback of the BOW approach is that it assumes a positive correlation between word frequency and relevance. In other words: the more the decision mentions a particular word, the greater the likelihood that word is indicative of the decision’s content. It also performs better if each word refers to an independent concept (i.e. “claimant” does not equal victim), as it disregards that different words may refer to the same legal concept and that different legal concepts may fall in the same general category. For this reason, building and using ontologies (knowledge systems) are crucial in legal text mining.
Next upcoming weeks, I will actually use text classification algorithms with a richer set of features to analyze the decision. Let me know what you think!