
As some time has passed since I posted the last QNL, in this QNL I will analyze the last six weeks of Dutch jurisprudence, from November, 16 to December, 30.
Besides the weekly statistics, I will zoom in on the utility of the website’s categorization (uitspraken.rechtspraak.nl) of cases for corporate finance lawyers. In particular, I use a Latent Dirichlet Allocation (LDA) model to analyze potential improvements of this categorization. These models have the potential to improve the categorization.
Cases by institution
The total number of cases published in the last six weeks is 2389. As expected (see previous posts), most published decisions are issued the Raad van State (RVS) and Centrale Raad van Beroep (CRVB):
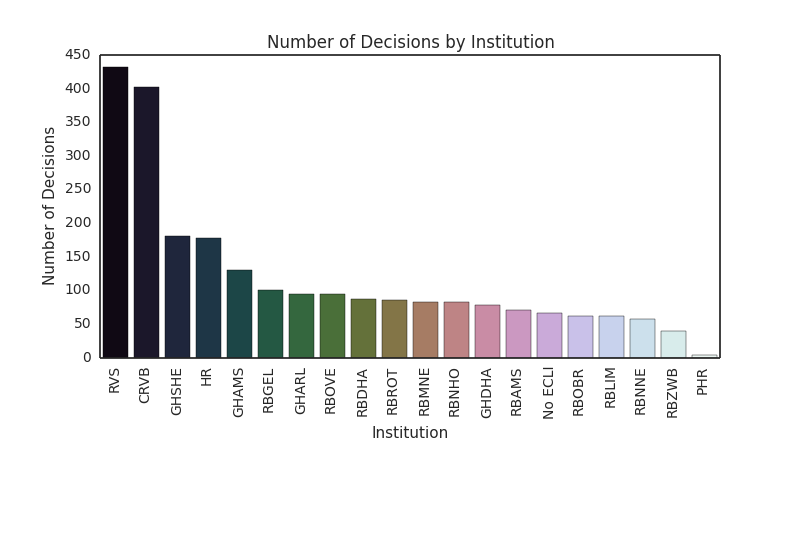
A closer look at these twin peaks shows that the majority of RVS decisions are in the area of administrative law (80.3%, 347 of 432). This makes sense, as the General Administrative Law (Algemene Wet Bestuursrecht) confers jurisdiction to the RVS in a wide range of administrative law areas. However, the category is broad and therefore not very informative. The majority of CRVB decisions are in the area of social security law (88.8%, 357 of 402). Again, a very broad category. The Supreme Court has published 178 cases in this period, but approximately 25 of those decisions are RO 81 decisions (see this post for an explanation of this type of decisions).
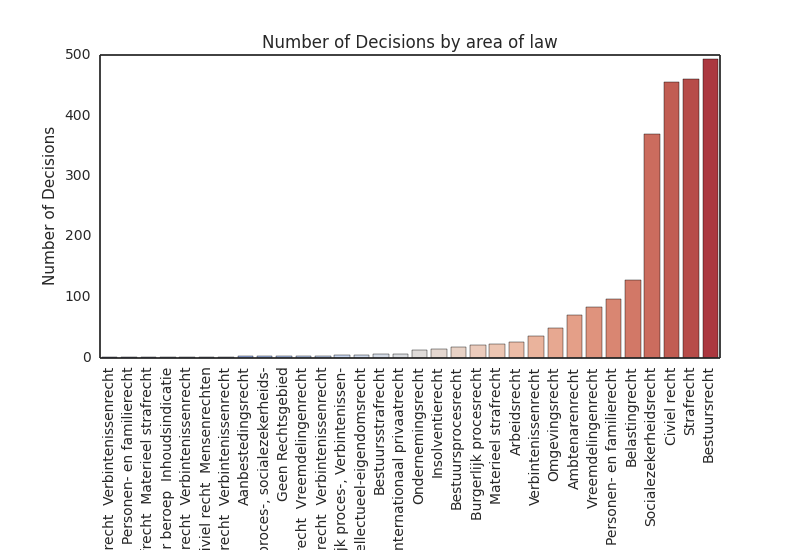
Cases by area of law
The top 5 areas of law in terms of volume, have not changed either. Administrative law, civil law and penal law comprise the top 3, followed by social security law and tax law. Since nearly all of the remaining areas of law can be subsumed under the three front-runners, the tail of the frequency distribution is not very interesting.
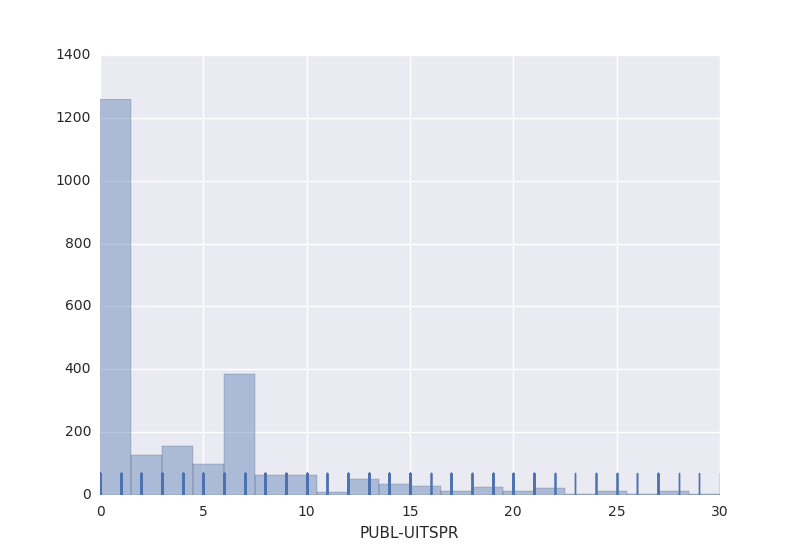
Throughput time
Plotting the elapsed time between the date of the verdict and the date of publication for each case, reveals that courts publish their decisions on the same day. There are a number of outliers at the far end. In three instances, more than 26 days elapsed between the verdict and the publication of a decision of the Amsterdam Court of Appeals. Other institutions whose decisions are at that far end of the distribution are a number of civil courts of first instance and the Arnhem-Leeuwarden Court of Appeals. Note that this is not a critique, especially since the underlying reasons for the delay are not known.
Topic models: towards an improvement of the case categorization interface
Instead of a plain vanilla n-gram frequency analysis, I focus on another useful technique for categorization of court cases: topic modelling using Latent Dirichlet Allocation (LDA).
The case for improving the website’s categorization of court cases is compelling. Try using the website’s advanced search interface (link). The official categories may be useful for doctrinal purposes, but for the corporate finance practitioner they are impractical. Whether his practice is more focused on litigation or on transactions, this practitioner is confronted with a framework of rules that does not map on categorizations of European versus national origin, private law versus public law and private law versus penal law. Instead, the day-to-day legal analysis in the finance practice revolves around particular legal acts and concepts: offering securities, providing security, director liability, to name a few. The legal rules applicable to these acts and concepts stem from various doctrinal categories, but those categories matter less for practical purposes. In order to promote information efficiency, it makes sense to tailor the official categorizations to the needs of legal practice.
Lawyers with a data science background could play an important role here.
For a thorough explanation of topic modeling using LDA, I can recommend reading David Blei‘s work. Generally, topic modeling starts from the assumption that documents exhibit multiple topics. More specifically:
- each topic is a distribution over words;
- each document is a mixture of corpus-wide topics; and
- each word in the document is drawn from one of those topics.
The goal is to infer hidden variables (topic structure, i.e. topics, proportions of topics per document and topic assignments per documents) from the documents, which consist of observed variables (words). If the previous assumptions hold, the LDA is the generative process by which a joint probability distribution of the hidden and observed variables comes about. In order to compute the topic distribution a Bayesian statistical model is used and Gibbs sampling is used to approximate that model with empirical data.
A topic model for finance-relevant case law
Fitting a LDA topic model to a subset of the case law, a list of finance topics could be generated. In order to narrow the list of possible topics, I narrow the set of cases to cases with references to the Civil Code (Burgerlijk Wetboek) or the Financial Supervision Law (Wet op het financieel toezicht), 476 cases in total. The following topics are estimated:
Topic 0: verweerder werknemer verzoek kantonrechter arbeidsovereenkomst verzoeker verzoekster
Topic 1: appellant hof geintimeerde beroep geintimeerd hoger grief
Topic 2: moeder minderjar vader de hof minderjarige man
Topic 3: man vrouw hof rechtbank per partij bedrag
Topic 4: of verdacht slachtoffer en rechtbank ten medeverdacht
Topic 5: eiser verweerder percel rechtbank artikel gemachtigd verzoek
Topic 6: the cramm of to and interpolis har
Topic 7: deskund rapport achmea schad har rechtbank of
Topic 8: artikel besluit beroep uitsprak lid die niet
Topic 9: eiser naam har tzl bestuurder gedaagd eo
Topic 10: naam afm niet accountantskamer dsb colleg verwijt
Topic 11: gedaagd eiser eiseres gedaagde vorder sub vonnis
Topic 12: bedrijf en of stichting medeverdacht obligatiehouder bestuurder
Topic 13: gemeent appellante huurovereenkomst partij woning huurder overeenkomst
Topic 14: niet die als om ook dit dez
Topic 15: bedrag overeenkomst betal rechtbank niet dez artikel
Topic 16: art vorder zak shell milieudefensie getuig die
Topic 17: gedaagde artikel propertiz dahabshiil nam websit bkr
Topic 18: of en belegger bedrag verdacht daaromtrent onder
Topic 19: bank beher abn vorder amro sns rabobank
Among the found topics, some reveal a potentially interesting set of topic words. Topics 10, 12, 15, 18 and 19 seem especially relevant to the corporate finance practitioner. However, the collection of documents in the subset (small) and the time period of six weeks (short) may introduce some bias in the list of topic words. That being said, with some refinements LDA topic models could improve the informational efficiency of the website’s categorization.